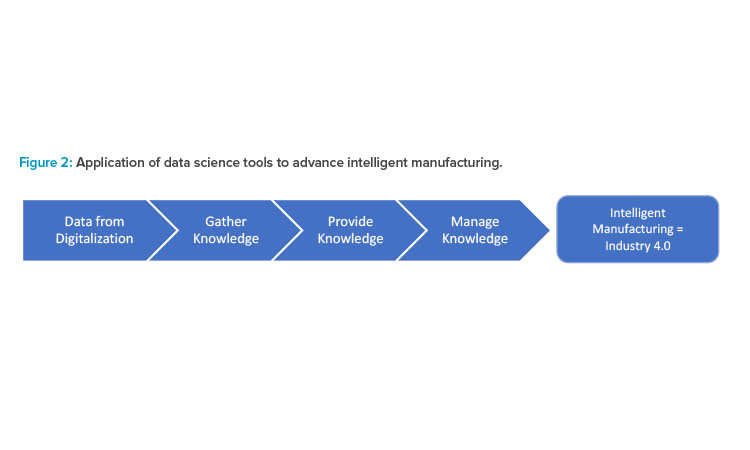
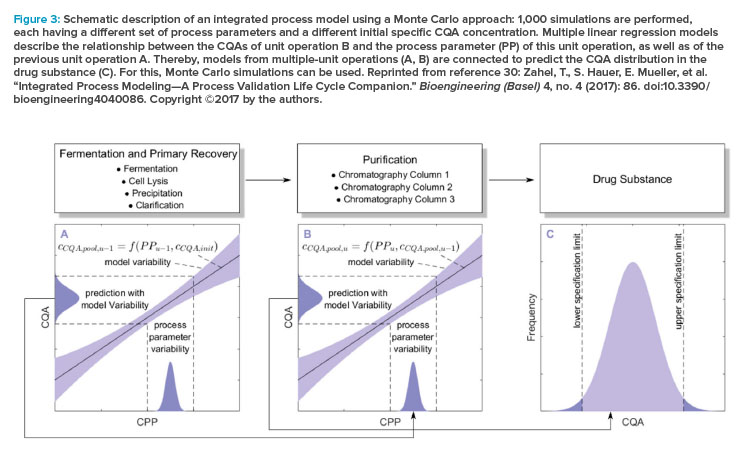
Data science is the most recent data, information, knowledge, wisdom (DIKW) concept. In the bioprocessing industry, it is used to turn data into information, which can then be transformed into knowledge applicable across the product life cycle. Thus, it permits organizations to follow the ICH Q12 guideline for life-cycle management by providing a data-based set of established conditions (ECs). Data science also allows intelligent processing in control strategies according to the sequence of primary data collection, followed by the evaluation of information, generation and provision of knowledge, and, finally, a high level of manufacturing intelligence and comprehensive understanding. Figure 2 illustrates how data science tools enable intelligent manufacturing, which, in our view, is the main goal when following Industry 4.0 principles.
Data Science Prerequisites
Data Alignment, Contextualization, and Integration
According to surveys, data scientists spend the majority of their work time preparing and processing data. Having worked for many years as and with data scientists, our experience upholds this finding. Up to 80% of the data scientist’s time is dedicated to data alignment, cleaning, and contextualization, and setting up test data sets. Data scientists must repeat these basic work tasks on a daily basis because there is an unlimited amount of possible and different data formats, many of which are unsuitable or nonstandardized. As a result, only about 20% of the highly skilled data scientist’s time is available for building training sets, writing algorithms, building and refining models, and delivering knowledge.
The intellectual property of pharmaceutical companies is mainly present in the form of data.
This arrangement is not cost-effective. Data processing and organization do not deliver any value by themselves, even though they are indispensable prerequisites to advancing drug development and production. Moreover, manual data manipulation bears the risk of introducing human errors into the data set.
There are multiple reasons for this awkward predicament. One is the vast diversity of data and data applications in the pharmaceutical industry—material supply information, data on the history of the used strains, experimental design data, process raw data, analytical data, derived process data, associated metadata, statistical models, mechanistic models, hybrid models, single-unit operation models, holistic models (e.g., integrated process models and digital twins), analysis workflows, validation workflows, and batch records, to name just a few. (A digital twin is a virtual representation of a physical or intangible object existing in the real world. With a twin, we can design experiments, predict process outcomes and even optimize the process in real-time.) Currently, all these types of data are usually stored as paper records or in nonstandardized relational databases (such as programming scripts) or tabular files. As we have noted, converting such data to knowledge is the primary purpose of data science. However, other essential prerequisites must be implemented before the conversion can succeed.
Standards and Interfaces
Open-source, interoperable, platform-independent, widely accepted and implemented standard formats would help reduce the amount of time currently used for data processing and contextualization. However, given the market economy and the speed of development, the IT industry is affected more than any other industry by proprietary de facto standards, such as using Microsoft products. These standards prevent an efficient reuse of algorithms and data science tools.
Various attempts are currently under discussion for implementation of open-source standard formats. For example, the Allotrope Foundation aims to define and implement a common data format that focuses on the contextualization and linking of analytical data. The lofty goals of the Allotrope project are much appreciated, and the project is well supported by discrete manufacturing industries. A similar project, with focus on the process industry, is Data Exchange in the Process Industry (DEXPI). This initiative aims to set up an ISO standard to enforce a common data storage and exchange approach.,
To use open-source standards and formats in pharmaceutical manufacturing, regulated companies must adopt proper controls. For example, the US FDA’s predicate rules influence which tools and systems are used in computer validation.
Open-source projects are far from general implementation, and it is unclear whether any of these approaches will become a commonly used stand-ard. There is a danger that these efforts will not result in applied tools. Sometimes, the overhead to implement an interface in a standardized format is simply too high relative to the cost of an unstandardized format such as a simple CSV file. To encourage the adoption of open-source standard tools, leading software providers, application developers, and industrial organizations need to commit to making tools and their related interfaces easy to apply and implement.
The historic evolution of the Open Platform Communications (OPC) standard is a noteworthy model for other internet of things (IoT) applications. An OPC interface is used in the automation industry for communication between different software tools. Previous OPC standards had several technical drawbacks that limited their use for the IoT. One of its biggest issues was that they were based on Microsoft’s DCOM specification. Communication in a complex network was usually only possible with workarounds such as additional OPC tunnel tools. During the last decade, collaboration among different parties resulted in a unified architecture standard, OPC-UA, which is a generic, open-source, platform-independent, network- and internet-ready interface standard with built-in advanced security features. OPC-UA is functionally equivalent to the older versions of OPC but is extensible and allows modeling of data as more complex structures. The named features make OPC-UA the preferred standard for IoT applications.
Data Security and Data Integrity
In the pharmaceutical context, data security and following GAMP® guidelines are highly critical. The intellectual property of pharmaceutical companies is mainly present in the form of data. Research and development data, drug manufacturing recipes, process metadata, and batch records all contain massive amounts of information that can be potentially converted into valuable knowledge. In the past, pharmaceutical companies protected their data using organizational and technical firewalls, resulting in data segmentation. Parts of a company’s data infrastructure today are strictly shielded from other parts by using separated networks. Obviously, a high interconnectivity of devices and systems counteracts such security approaches. Pharma 4.0™ demands devices, users, and data scientists to be part of a common network. At the same time, access permissions need to be handled with fine granularity, providing just those access permissions to each element in the network that are actually required. To realize the Pharma 4.0™ vision, companies need to rethink their IT security fundamentals, deriving security systems from the internet of information and implementing them into the IIoT.
Data integrity is a related aspect of data security. Data integrity often refers to the completeness, consistency, and accuracy of data. According to US FDA guidance, “Complete, consistent, and accurate data should be attributable, legible, contemporaneously recorded, original or a true copy, and accurate (ALCOA).” With data being the foundation of work and the basis for decisions, data integrity is crucial to the pharmaceutical industry. Regulatory agencies reacted to the lack of data quality and integrity in the past by publishing guidelines highlighting the importance of data integrity for the industry and for the patient safety. , , To guarantee unequivocal data integrity, centralized IT systems have to be reassessed due to the complexity of validation of good data housekeeping, and alternative solutions need to be discussed. One approach is to separate parts of the data by, for example, storing them in a distributed ledger that is not under the control of a single party and therefore allows better control of data management.
Sandboxes and Test Environments
In discussions of data scientists’ challenges and efforts, the actual implementation of developed algorithms and tools in production environments along the product life cycle is sometimes overlooked. Often, data scientists can quickly develop an algorithm or set up a model. However, it is not always clear how these results can be brought into production and used in a real-time context.
Current manufacturing environments are quite different from the development environments of data scientists. Data scientists are eager to use the latest tools and state-of-the-art technology. In contrast, automation specialists setting up the production environments are more cautious about the adoption of new technology that might put safety at risk. They usually rely on older, but time-proven, stable tools and software products. Bringing these two worlds together is a challenge, which is rarely addressed early enough in the implementation process.
Similarly, algorithms developed by data scientists in their development environments cannot simply be copied and pasted into the production environment. Often, a finished algorithm is just a prototype that proves feasibility. Too many promising tools never end up in a production facility.
Sandbox mode development and test environments can help overcome these issues. Development of data science tools requires time-consuming exploration involving many feedback cycles, such as agile development strategies. Data scientists need virtual production environments to test their algorithms and software solutions to improve these tools’ applicability for commercial GxP-compliant drug manufacturing.
Process Development Tools
Factors such as increased competition and resulting cost pressures in the biopharmaceutical market, new modalities for personalized medicine, and reported threats of drug shortages provide incentives for organizations to develop, in the words of the Janet Woodcock, Director of FDA CDER, a “maximally efficient, agile, flexible pharmaceutical manufacturing sector that reliably produces high-quality drugs without extensive regulatory oversight.” Specific hands-on goals in process development can be summarized as follows:
- Accelerate bioprocess development by avoiding iterations and deploying strategies to reduce the number of experiments.
- Develop universal scale-down models to accelerate process characterization, allow troubleshooting, and avoid unexpected scale-up effects.
- Deploy process analytical technology (PAT) strategies to (a) provide improved real-time operational control and compliance, (b) serve as an objective basis for process adjustments, and (c) provide a comprehensive data set for technology transfer decisions.
- Implement strategies to target integrated bioprocess development rather than optimizing single-unit operations only.
- Capture platform knowledge to achieve synergies with other products and extrapolate to other process modes such as continuous manufacturing.
- Allow life-cycle management aligned with ICH Q12, including holistic knowledge and product life-cycle management. This should include clear feed-back loops from manufacturing into process development to establish holistic manufacturing control strategies.
Development-Oriented Tools
Table 1 lists data science tools that can be used in the bioprocessing life cycle. When an organization has a data management system in place that follows ALCOA principles, these tools can address almost all industrial needs.
Statistical tools for business process workflows
Multivariate analysis (MVA) has been used for decades, and several MVA-dedicated software tools are available to improve business process workflows. More advanced methods have recently been developed, and respective good practice guidelines have been established. The goal is to identify correlations between process variables, raw material attributes, product quality attributes, and the metadata from electronic batch records or electronic lab notebooks (ELN), and use those correlations as data-driven models to both establish control strategies (e.g., in stage 1 validation tasks) and generate hypotheses for mechanistic investigations and improved process understanding.
Digitalization will furthermore allow seamless interfacing between operational historians, laboratory information management systems, ELN, and so on, and should include automated feature extraction from 2D data (e.g., spectroscopic or chromatographic data) and 3D data (e.g., from flow cytometry or microscopy). Inspired by FDA validation guidelines, such tools should be integrated in a business process workflow or in process maps; for example, they might be linked to risk assessments, which in turn are facilitated by data science. This integration will help organizations establish clear traceability of decision-making along the manufacturing process development and manufacturing process characterization steps. For example, power analysis is used to reduce the risk of overlooking a critical effect of potential critical process parameters (CPPs) on critical quality attributes (CQAs), and to justify the proven and acceptable operating ranges.
Table 1: Mapping data science tools to industrial needs in the bioprocessing life cycle (“X” indicates a main application).
| Tools |
| Industrial Needs |
Statistics and
Data Science
Workflows |
Digital Twin
Generation |
Digital Twin
Deployment |
Integrated
Digital Twins |
Digital Twin
Validation,
Evolution,
Maintenance |
Real-Time
Environments |
Process Control
Strategies |
Production
Control
Strategies |
Accelerated process
development |
X |
|
X |
X |
|
X |
X |
|
| Scale-down models |
X |
X |
|
X |
|
|
|
|
| PAT |
|
|
X |
X |
X |
X |
X |
|
Integrated process
development |
X |
|
|
X |
|
X |
X |
X |
| Platform knowledge |
X |
X |
|
X |
X |
|
|
X |
Life-cycle
management |
X |
|
|
X |
X |
|
|
X |
Workflows for model and digital twin generation
Since the publication of the ICH Q11 guideline, the use of first-principle models (which can be implemented in digital twins) is encouraged along the product life cycle. These models are also perceived to be a significant enabler for life-cycle management in accordance with ICH Q12., However, a digital twin should not be the product of a single modeling expert, because the acceptance of the model as well as life-cycle maintenance will fade out when the expert is no longer available. As viable alternatives, concise workflows for model generation have been in place for more than a decade. These workflows are known as good modeling practice and use classical mathematical tools for model calibration—such as sensitivity, practical identifiability analysis, and observability analysis—for deploying the model with a suitable PAT environment.
As data are made available in cloud solutions, digitalization will further enable software-as-a-service (SaaS) solutions for the generation of minimum targeted models, in which mechanistic links, as assembled and uploaded by the academic community, are tested for suitability to the given data set and modeling goal. Hence, existing data science workflows are facilitated by novel cloud solutions, resulting in an accelerated, sound, and science-based approach to generate digital twins.
Model and digital twin deployment
Models capture comprehensive process understanding. Hence, they are perfect tools to provide knowledge for manufacturing intelligence. In technological language, models can be deployed in a multiparametric control strategy in a real-time context. Model-based control or model predictive control (MPC) software sensors are well established in the conventional process industry, but they have hardly been used so far in value-added process industries such as the biopharmaceutical sector. Why not?
One issue is the lack of appropriate knowledge management tools and strategies. Once data are provided to the modeled process in a real-time con-text, knowledge management tools are needed to check whether the model and the underlying knowledge are still valid. As ICH Q12 emphasizes, the industry needs computational model life-cycle management (CMLCM) strategies, which are also an integral part of product life-cycle management, to enable feedback loops and continuous improvement of the process chain and product life cycle.
The execution of the knowledge-based strategy will lead to intelligent manufacturing and the realization of Pharm 4.0™. Digital twins can help enable us to achieve this goal in variety of ways.
It is widely recognized that digital twins can be used for experimental design. For example, digital twins help predict optimal feed profiles to a certain target function such as the optimum time-space yield. Recently, digital twins have also be used for automated model-based redesign of experiments; in this context, the digital twin is deployed in real-time and informational content is maximized concurrent to the ongoing experiment., These approaches clearly outperform classical design-of-experiment approaches in terms of both the number of experiments and the accurate identification of process parameters critical for optimum process performance.