Using Technology for Continuous Process Verification 4.0

In this article, potential Pharma 4.0™ technological solutions that can enhance continuous process verification (CPV) 4.0 are discussed. The necessary paradigm shift will allow companies to predict deviations more accurately, perform root cause analysis (RCA), ensure data integrity and GxP compliance, and ultimately be more competitive in a highly regulated industry.
This article is the second part of the “Reimagining CPV for a Pharma 4.0™ World” article published in the May–June 2022 issue of Pharmaceutical Engineering® .1 In that article, the business requirements were analyzed. The goal of this article is to showcase potential technological solutions that can enhance CPV for a CPV 4.0 by matching already available Pharma 4.0™ technologies with specific business requirements. This article is based on the defined framework and the implementation approach described herein.
CPV 4.0 Value Proposition
The end goal of a CPV implementation is to ensure process robustness through the adequate and timely monitoring of processes. The best way to ensure robust processes is by predicting potential deviations that could affect batch performance. Applying Pharma 4.0™ technologies to CPV programs will enable this vision for predictive monitoring by making it technically feasible to:
- Predict deviations more accurately with artificial intelligence (AI)/machine learning (ML) algorithms
- Perform RCA from a holistic viewpoint
- Ensure data integrity and GxP compliance in predictions and RCA
Thinking further, CPV 4.0 offers a compelling dual advantage: It can predict deviations in real time and it can eliminate lengthy and costly back-end quality control testing upon batch completion. Both advantages lead toward real-time release.
From a User-Centric to a Data-Centric Model
The foundations of a CPV 4.0 program lie in the data in the true “big data” sense (high volume, variety, validity, and velocity). CPV 4.0 requires a paradigm shift in the pharmaceutical industry. The current manufacturing scenario is built on a user-centric data consumption schema, where the users establish which data are needed for their jobs, and then the information technology (IT) and quality assurance (QA) departments make the necessary system modifications to get that data in the right structure, context, and level of certification.
This ad hoc strategy is rigid, expensive, and slow. For example, based on benchmarking different cases, inserting four additional data points as tags into an existing data store would require an entire week of IT and QA collaboration. Costs include the direct full-time employee costs of making the change and the opportunity costs of IT and QA resources. This slow and rigid strategy runs counter to the flexibility and efficiency required in a constantly changing environment.

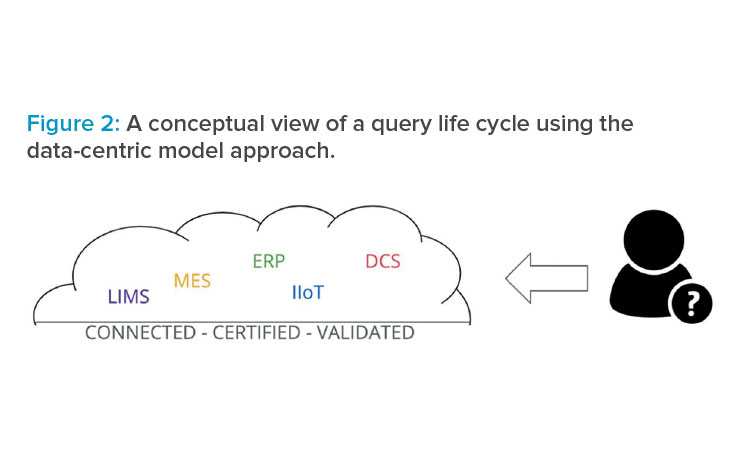
Figure 1 illustrates the query life cycle of a user-centric model where all the previously mentioned strategies were applied, making each query more costly and slower.
New manufacturing trends indicate that the proper data gathering and access scenario should be based on the manufacturing intelligence ontology (MIO), where the actors and their interactions are both considered.
The most challenging steps in developing a CPV 4.0 technical solution are related to the data workflow: data acquisition, data contextualization, data modeling, and data visualization.
The MIO leads to a data-centric model, where users access data from a regulated data hub and where all proper data contextualization and certifications only have to be performed once. In that case, the user has direct access to the qualified data, which is more efficient and faster because all the data silos are broken down, as shown in Figure 2.
Key Elements of a Data-Centric Model
Cloud Infrastructure
A cloud-hosted data store is ideal for the large volume of heterogeneous data required for a CPV 4.0 approach. Data from disparate sources (i.e., process, environment, human resources, maintenance) are automatically collected and transmitted to the cloud, reducing the inherent compliance concerns regarding manual data collection. This has the dual effect of breaking down data silos and enhancing data integrity.
The cloud offers many benefits and risks to a regulated organization. Interoperability and flexibility are paramount with the cloud. Scalability is a key benefit. CPV 4.0 needs a lot of computation power for ML model training and predictive analysis. The cloud offers an elastic resourcing paradigm for storage, computing, and networking resources. Fault tolerance is inherent in a cloud environment, as the operational resources are decoupled from the physical world of servers, switches, and storage. A major risk for regulated organizations is the loss of direct control over their data. If proper controls are not put into place, data security and data integrity may be compromised.
There are many models for cloud deployment, but the virtual private cloud model is most amenable to regulated organizations. A virtual private cloud is a private cloud run on shared infrastructure. It allows for the company’s cloud resources to be isolated from that of other individuals or organizations. This encapsulation increases data security and privacy and reduces risk.
One consideration when using the cloud is the financial impact on an organization. The total cost of ownership (TCO) of IT infrastructure is difficult to ascertain as the mode of procurement shifts from a traditional capital expenditure (CAPEX) model to a subscription-based operating expenses (OPEX) model. The elastic nature of resource allocation in the cloud means that the cost will vary. An increase in computing power requirements for AI model training brings a higher price tag, so careful planning is necessary to avoid surprises. The cloud allows for a reduction in IT maintenance costs, as the subject matter experts from the cloud service provider are leveraged to ensure the security, reliability, and availability of the cloud. The elimination of CAPEX costs in the cloud can lead to a TCO that is one-third that of traditional IT infrastructure.2
It is becoming more common for larger cloud service providers to add ALCOA+ (Attributable, Legible, Contemporaneous, Original, Accurate + Complete, Consistent, Enduring, Available) considerations to their offerings, making it easier for a regulated company to perform GxP activities in the cloud. The regulated company is responsible for including its use of the cloud in its quality management system (QMS) and other quality documentation. QMS considerations include:
- The means of creating and managing user accounts for administering cloud services
- Training appropriate personnel to perform their job functions in the cloud
- Internal auditors being familiar with the cloud and any auditing tools or resources available to help auditing within the cloud
- Performing supplier evaluations to establish the quality practices of a cloud service provider
It is important to build quality concepts into a service level agreement and to have a supplier quality agreement that addresses the concepts of reliability, availability, data security, privacy, change management, disaster recovery, communication and reporting of issues, and data access.3 Data regionality may also be a concern in some applications. Ultimately, responsibility for and ownership of the data remain with the regulated company regardless of where data are stored, so the company must be vigilant when leveraging the cloud for a CPV solution.
Data Contextualization
Organizing data in a meaningful manner has obvious advantages for the scalability of a solution. For example, if we are capable of contextualizing information for a batch where a feature analysis is needed, multiple batches need to be extracted for this analysis, facilitating the whole process. Furthermore, when we have similar processes, there is value in having similar data structures that can help scale the data analysis faster. For example, for a group of process units such as reactors or freeze driers that run very similar processes, the data structures could be set up in a similar manner.
When referring to an industrial process, we often describe data context as having two main components: asset context and batch event context.
Asset context
In asset context, we organize information with the physical representation of our factory assets as a baseline. Very often this is described as an asset digital twin, a collection of which may support and be components parts to the digital twin of a factory.
As an example, we could take any asset inside a factory that participates in a process and associate all the data belonging to it. This will provide a good representation of the variables that can be monitored inside this process.
When creating an asset context, it is relevant to decide between different possible standards. A hierarchical representation with different levels will facilitate this contextual organization, but it will require an alignment with the content/concept associated to each level.
Batch event context
Batch event context is especially important when trying to categorize data. It is important to have not only a digital twin representation of all the assets that participate in a manufacturing process (such as motors, rotors, reactors, and valves), but also a good process context of all the events. For example, if we want to retrieve data from a certain equipment unit belonging to a certain batch (or an operating procedure), it is imperative that this process digital twin is well identified. This is an important step before working on advanced modeling or AI techniques because our data will be much better prepared for analysis.
The ISA 88 batch standard,4 which provides a good guideline for creating an equipment/asset hierarchy as well as a process hierarchy (asset digital twin and process digital twin), could be helpful for categorizing data.
Value Drivers and Compliance Requirements
The most challenging steps in developing a CPV 4.0 technical solution are related to the data workflow: data acquisition, data contextualization, data modeling, and data visualization. Each of these steps has its own possible technical solution with unique compliance requirements.
Real-time data acquisition is key to breaking down the data silos and avoiding manual data handling. This approach will reduce time and effort, data integrity risk, and nonquality costs. Compliance requirements provide guidance on how data should be stored. Data must always be attributable, stored in a legible format, have timestamps for each life cycle step, be documented by a X.509 certificate granted in origin, and have build usage and metadata storage. In addition, the data location (regionality) and data storage (reliability) must be properly managed.
The technical requirement for data contextualization is to have scalable data models so that we do not have to start from scratch when adding new equipment and/or data sources. Compliance requirements exist for how data are normalized. Contextualization is done in the cloud with hot, warm, and cold access, and time synchronization and updates are under change control. A possible technical solution is creating context models in JavaScript Object Notation (JSON) format (the format of “big data”). JSON allows for the management of structured and unstructured data.
Data modeling (statistical or ML) allows predictions of and alerts for out-of-specification and out-of-trend data and can encourage operators to take proactive action to bring the process closer to the “golden batch” state. In this case, the technical need is to have flexible computational power (serverless cloud technology could help here) depending on the ML models to create, train, or execute.
In the end, data visualization is a real-time monitoring solution that enables proactive actions. Compliance requirements exist for how data are used. Usage must be logged and tracked, security and access rights must be controlled, data must be monitored for risk assessment, continuous backups are necessary, and data retirement must be managed.
The CPV 4.0 Roadmap
The vision of CPV 4.0 cannot be considered complete without a clear end state and a roadmap for how to get there, which is difficult to define given the status of the industry on CPV implementation.
One of the main roadblocks to evolve through a CPV 4.0 roadmap is that there is no AI model life cycle strategy for manufacturing, where an AI model is built, qualified, and validated into a specific process.
However, applying AI in a CPV context is achievable through a strategically developed algorithm qualification process. Discussions around AI algorithm qualification processes have already begun. Several papers have been published, but agencies, manufacturers, and suppliers are still looking for an official standard procedure to qualify AI algorithms, allowing their use in a regulated environment.
ISPE and GAMP are working in this area; for example, see Pharmaceutical Engineering, November–December 2019.5 ISPE also recently published the GAMP® Good Practice Guide: Enabling Innovation6 that expands upon this discussion.
Conclusion
We are in the middle of a considerable challenge: a paradigm shift in a reputably risk-averse regulated industry to apply more innovative and cutting-edge technology to stay competitive.
In recent years, a few trends have emerged in the pharmaceutical industry: the evolution of treatments from blockbusters to personalized medicine; the pressure of being more competitive in a global market; and an industry in which the big companies seem to be more interested in mergers and acquisitions than developing their own pipelines. The need to change the paradigm is more urgent than ever.
As much as markets and companies evolve, technology is evolving even faster. Most ML algorithms were designed decades ago. It is only recently that the democratization of technology has allowed for the viability of implementing them.
Further, when technology is available and compliance aspects are addressed, the main roadblock for a CPV 4.0 rollout is the cultural mindset.
The Acatech Industrie 4.0 Maturity Index7 emphasizes that the key to the successful implementation of any technology in a manufacturing organization is through the realignment of the company culture.
The focus should be on two specific principles: a willingness to change and the adoption of social collaboration. The emphasis on change essentially means that companies should focus on the value that can be derived from allowing mistakes, innovating, and pushing for decisions based on data and its analysis. Social collaboration means democratizing decision-making, encouraging open communication, and establishing confidence within the workforce in the processes and systems chosen to enable a digital transformation. The workforce, from management to workers on the manufacturing line, must be ready and willing to adopt to these changes.
These concepts translate directly to a CPV 4.0 approach, as regulated companies seek to employ technologies such as the cloud and AI/ML to improve processes. The chicken-and-egg cycle must be broken: processes are not being improved because there is not enough data (in quantity and quality), and ML/AI is not being used because it will require revalidation of the process.
Finally, the change management process is key to advancing through the Pharma 4.0™ paradigm shift. Creating centers of excellence and applying governance models would help to unblock situations within big organizations.
About the Authors



