Risk-Based Continued Test-Method Performance Verification System

Good data are a characteristic of good science. Quality data are arguably more important today than ever before and are considered by many to be a corporate asset because they are used to develop products and processes, control our manufacturing processes, and improve products and processes when needed.
The US FDA and USP have provided guidance for developing, validating, and verifying effective test methods that will deliver quality data.2, 3, 4 Their guidance calls for continued method performance verification (CMPV) to verify a test method’s performance over its life cycle. At the same time, there has been renewed interest in developing risk-based methods of all types.5 Fortunately, we have concepts, methods, and tools available to build assessment and mitigation of risk into a test-method performance verification system.6
The FDA calls for CMPV.2, 3 However, there are three critical risks associated with the long-term use of the method.
- First, the method’s precision in terms of reproducibility and repeatability decreases over time. (Note: Although the pharmaceutical industry often uses the term “reproducibility” to describe between-laboratory variation in measurement results, this article addresses within-laboratory reproducibility, which measures variation due to different analysts, instruments, and other factors at a given laboratory.)
- Second, the method does not meet acceptance limits (specifications).
- Third, management does not pay sufficient attention to method performance.
This article discusses CMPV methods that effectively reduce these critical risks.
Blind Controls to Assess Method Performance Stability over Time
An effective way to assess the long-term stability of a test method is to periodically submit “blind control” samples (also referred to as reference samples) from a common source for analysis along with routine production samples. Blinding the samples ensures that the analyst cannot determine the difference between the production samples and the control samples, and, as Nunnally and McConnell have stated, “There is no better way to understand the true variability of the analytical method.”7
The control samples are typically tested two or three times (depending on the test method) at a given point in time. The sample averages are plotted on a control chart to evaluate the stability (within-lab reproducibility) of the method. The standard deviations of the repeat tests done on the samples are plotted on a control chart to assess the stability of the repeatability of the test method. The deviations of the sample averages from the overall mean measure the within-lab reproducibility of the method. The standard deviation of the test results from the sample mean measures the repeatability of the method.
Weitzel and colleagues described a six-year study in which control samples were used to monitor an assay measurement process.8 The blind control samples were drawn from a common master control batch and periodically submitted for lab analysis. Six analysts (A, B, C, D, E, and F) tested the 48 samples in duplicate over the six-year period. See the Appendix for a summary of the results.
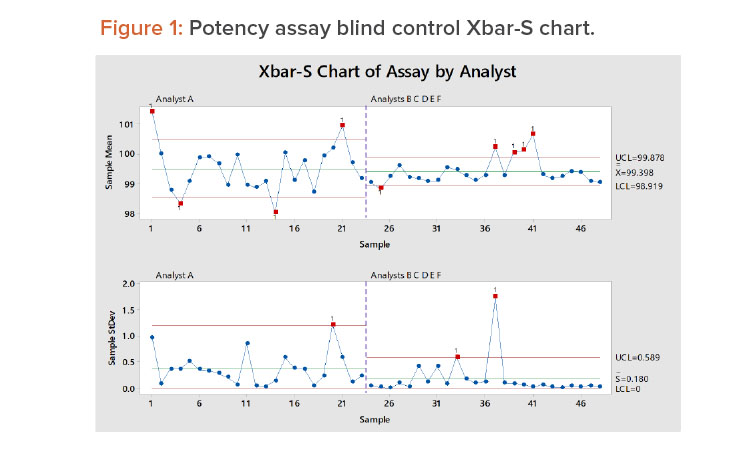
Figure 1 shows the control chart for the 48 samples. The first 23 samples were tested by analyst A, and the remaining samples were tested by the other analysts. In Figure 1, we see:
- Analyst A has more within-lab reproducibility issues; several sample averages are outside the control limits.
- There are some within-lab reproducibility issues around samples 37–41; these are principally attributed to analyst C (see the results for analyst C in the Appendix).
- The variation for the other analysts is smaller than that of analyst A.
- The overall average is essentially the same for all analysts.
- Analyst A has larger test-to-test variation (repeatability) than the other analysts.
As we will discuss later, the overall method variation was found to be within the goal of the method.
“Sensitizing rules” are often used in conjunction with control limits to detect nonrandom patterns of variation (level shifts, trends, cycles, and so on), which may not be detected by the control limits.9 These rules increase the sensitivity of the control charts to detect small shifts. One important type of nonrandom variation is out-of-trend results.
Other metrics, such as system suitability test (SST) failures and out-of-limits results, can also be used to assess continued verification. This article focuses on monitoring the results of blind control samples and product stability test results because these test results are widely used and reflect how the test methods are used on a daily basis. SST results have the limitation of measuring only instrument precision, which does not take analyst variation and other sources on variation into account.
Test-Method Stability Metric
The control chart analysis tells us whether we have a measurement stability problem for the particular method being studied. But a lab will have several methods to worry about. Some stability problems are more important than others. This raises the question, “When should we worry about method stability?” The answer is when long-term variation represents more than 20% of the total variation. Note that:
Total variation = Long-term variation (within-lab reproducibility) + short-term variation (repeatability)
The analysis of variance (ANOVA) is used to separate the long-term variance from the short-term variance. ANOVA of the control sample data computes the percent long-term variation, which measures the stability of the test method over time (within-lab reproducibility). Long-term variation variance components less than 30% are generally considered good, with larger values suggesting the method may have within-lab reproducibility issues.10 Collins and associates also discuss the use of long-term variation to assess process stability.11
Control limits may be based on the replicate variation, and this may be an issue when looking for trends. In such a case, the run averages should be subjected to an individuals’ moving average control chart,9 which uses the short-term between-sample variation to calculate the control limits, as discussed by Snee.12
The process stability acceptance criteria for long-term variance are:
- Less than 20% variance indicates measurement process stability is not a problem
- Variance between 20% and 30% suggests that measurement stability may be a problem
- Greater than 30% variance indicates that corrective action may be needed
Figure 2 shows stable (top) and unstable (bottom) measurement processes. The top chart shows a stable process: The long-term variation is 21%, and all points are within the control limits. The variation is random, without trends, shifts, or cycles. This measurement process shows good within-lab reproducibility.
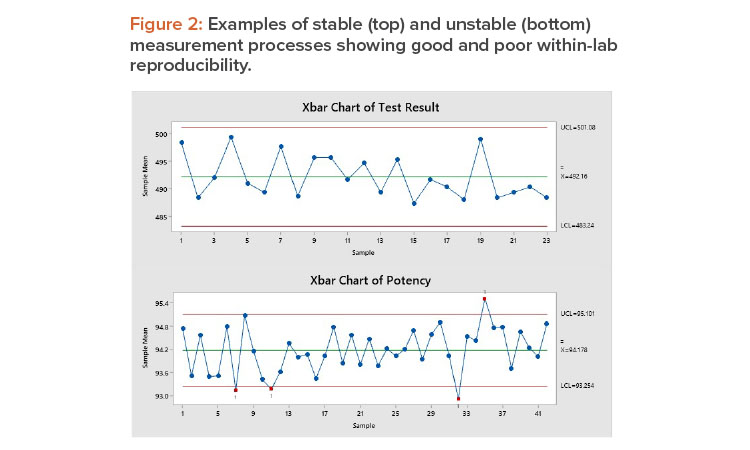
The bottom control chart shows an unstable measurement process: Five of the sample averages are outside the control limits, and the long-term variation is 58%, well above the 30% threshold for corrective action. This measurement process has poor within-lab reproducibility.
Control limits may be based on the replicate variation, and this may be an issue when looking for trends.
| ANOVA | |||||
| Source of Variation | Degrees of Freedom | Sum of Squares | Mean Square | F Ratio | P Value |
| Sample | 22 | 27.4654 | 1.2484 | 5.565 | 0.000 |
| Replicate tests | 23 | 5.1598 | 0.2243 | ||
| Total | 45 | 32.6252 | |||
| Variance Components Analysis | |||||
| Source of Variation | Measurement Characteristic | Variance Component | % of Total | Standard Deviation | |
| Sample | Within-lab reproducibility | 0.512 | 70 | 0.716 | |
| Replicate tests | Repeatability | 0.224 | 30 | 0.474 | |
| Total | Method variation | 0.736 | 100 | 0.858 | |
| All Analysts | Analyst A | Analysts B, C, D, E, and F | ||||
| Variation Type | Variance Component | % of Total | Variance Component | % of Total | Variance Component | % of Total |
| Within-lab reproducibility | 0.294 | 61 | 0.512 | 70 | 0.105 | 40 |
| Repeatability | 0.188 | 39 | 0.224 | 30 | 0.155 | 60 |
| Total for method | 0.482 | 100 | 0.736 | 100 | 0.261 | 100 |
| Goal for total | 1.0 | 1.0 | 1.0 | |||
The process stability acceptance criteria stated previously are recommendations that may be revised to suit specific applications. Also, when the criteria indicate that within-lab reproducibility and/or the total measurement variability may be a concern, one should look at how the variation in the test results compares to the acceptable limits (specifications) for the measurement method. This issue is addressed later, in the discussion of test-method performance capability indices.
ANOVA is used to calculate the portion of variation that is attributable to measurement repeatability and within-lab reproducibility.9 Table 1 shows the ANOVA of the test results for analyst A in the potency assay study as well as the associated variance components. In Table 1, we see that the sample-to-sample variation (within-lab reproducibility) is statistically significant (P = 0.000). Within-lab reproducibility accounts for approximately 70% of the total variation in analyst A’s test results, with the remaining 30% being due to repeatability variation.
Table 2 summarizes variance component statistics for all analysts, analyst A, and analysts B, C, D, E, and F. Here we see that variation for analysts B, C, D, E, and F is 40% of the total, a little above the 30% guideline. The good news is that the total variance goal of 1.0 is met by analyst A as well as the other analysts.8 So, although within-lab reproducibility may be high for this method, the results are within the goal for the method, which is relatively tight (relative standard deviation = 1%).
Product Stability Data to Assess Method Performance
The use of blind controls to assess measurement stability may have drawbacks. The first concern is that resources are required to maintain the control sample and insert the blind controls with the routine production samples. Furthermore, try as you might to keep the controls blinded, there is a risk that analysts will identify the blind controls and their purpose.
Whereas blind controls are used to routinely test a common product over time and observe the variation in the test results, Ermer and colleagues have noted that product stability data are another source of such data.13 In a product stability study, at least one batch of the product is typically tested using a common test method at various time points to assess the stability of the product.
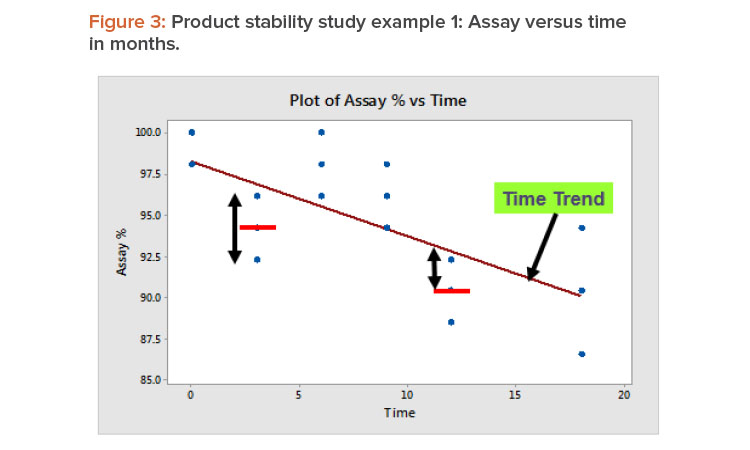
In product stability studies, after the time trend has been accounted for, the variation remaining is due to the test method’s repeatability and with-in-lab reproducibility. Figure 3 illustrates this by showing the relation between assay % and time measured in months for example 1 from Table 3. Repeatability is the variation around the sample mean, as illustrated by the data at three months. Within-lab reproducibility is the variation between the sample mean and the trend line, which is illustrated by the 12-month data.
Table 4 presents the ANOVA for example 1 (Table 3) as well as the associated variance components. In this case, reproduciblity accounts for 45% of the total measuremeent variation. The lack-of-fit P value (0.042) indicates that within-lab reproducibility is statistically significant.
Product stability study example 2 data show a more complicated data set (Table 5). Here, five lots have been put on a stability test. Duplicate test results were made at each of eight time points (0, 3, 6, 9, 12, 18, 24, and 36 months). Scatterplots of assay results versus time (not shown) identified linear trends for the different lots. The overall adjusted R2 equals 80% for these relationships. An examination of these plots shows several instances where the duplicate points are both above and below the trend line, indicating within-lab reproducibility variation. Variation between pairs of duplicate results reflects the repeatability of the method.
The ANOVA and variance components (Table 6) show that within-lab reproducibility accounts for 34% of the total measurement variation, which is above the stability acceptance criteria (<30%) discussed earlier. The ANOVA model allows for the slopes of the trend line to vary between lots. The residual variation is due to the test-method variation: within-lab reproducibility (lack-of-fit) and repeatability (replicates). The lack-of-fit P value (0.017) indicates that within-lab reproducibility is statistically significant, although it is not large as measured by the criteria for long-term variation criteria (acceptable <30%).
Assessing Test Method Capability
Measurement systems typically define acceptance criteria in terms of a goal standard deviation or upper and lower limits (USL, LSL), which are called “specifications” here.
| Test | Time month | Assay % |
|---|---|---|
| 1 | 0 | 98.08 |
| 2 | 0 | 100.00 |
| 3 | 0 | 98.08 |
| 4 | 3 | 92.31 |
| 5 | 3 | 94.23 |
| 6 | 3 | 96.15 |
| 7 | 6 | 100.00 |
| 8 | 6 | 98.08 |
| 9 | 6 | 96.15 |
| 10 | 9 | 96.15 |
| 11 | 9 | 94.23 |
| 12 | 9 | 98.08 |
| 13 | 12 | 88.46 |
| 14 | 12 | 90.38 |
| 15 | 12 | 92.31 |
| 16 | 18 | 90.38 |
| 17 | 18 | 94.23 |
| 18 | 18 | 86.54 |
| ANOVA | |||||
| Source of Variation | Degrees of Freedom | Sum of Squares | Mean Square | F Ratio | P Value |
| Time | 1 | 130.32 | 130.32 | 15.72 | 0.001 |
| Residual | 16 | 132.66 | 8.29 | ||
| Lack-of-fit | 4 | 71.02 | 17.76 | 3.46 | 0.042 |
| Replicates | 12 | 61.64 | 5.134 | ||
| Total | 17 | 262.98 | |||
| Variance Components Analysis | |||||
| Source of Variation | Measurement Characteristic | Variance Component | % of Total | Standard Deviation | |
| Lack-of-fit | Within-lab reproducibility | 4.21 | 45 | 2.05 | |
| Replicates | Repeatability | 5.14 | 55 | 2.67 | |
| Total | Method variation | 9.34 | 100 | 3.06 | |
| Time, months | Replicates | Lot 1 | Lot 2 | Lot 3 | Lot 4 | Lot 5 |
|---|---|---|---|---|---|---|
| 0 | 1 | 97.6 | 100.9 | 98.7 | 100.3 | 100.9 |
| 0 | 2 | 98.4 | 98.8 | 100.5 | 101.5 | 100.4 |
| 3 | 1 | 97.7 | 98.2 | 95.8 | 99.7 | 97.3 |
| 3 | 2 | 99.4 | 97.5 | 96.5 | 100.1 | 99.0 |
| 6 | 1 | 97.7 | 98.5 | 96.7 | 98.6 | 97.7 |
| 6 | 2 | 96.2 | 97.5 | 96.0 | 99.5 | 99.6 |
| 9 | 1 | 96.9 | 97.6 | 97.5 | 98.3 | 98.4 |
| 9 | 2 | 97.3 | 98.9 | 96.3 | 99.6 | 97.9 |
| 12 | 1 | 94.0 | 96.9 | 94.7 | 96.8 | 96.5 |
| 12 | 2 | 95.3 | 97.5 | 98.3 | 98.3 | 97.0 |
| 18 | 1 | 96.5 | 96.3 | 93.7 | 96.7 | 99.5 |
| 18 | 2 | 94.9 | 96.5 | 94.1 | 95.2 | 96.8 |
| 24 | 1 | 96.0 | 95.8 | 93.1 | 96.3 | 96.0 |
| 24 | 2 | 97.5 | 96.0 | 92.5 | 97.1 | 96.5 |
| 36 | 1 | 92.1 | 92.3 | 91.3 | 93.9 | 93.7 |
| 36 | 2 | 92.7 | 92.0 | 89.5 | 93.8 | 94.6 |
| ANOVA | |||||
| Source of Variation | Degrees of Freedom | Sum of Squares | Mean Square | F Ratio | P Value |
| Time | 1 | 312.58 | 312.57 | 265.68 | 0.000 |
| Lot | 4 | 22.81 | 5.7 | 4.85 | 0.002 |
| Time × Lot | 4 | 10.5 | 2.62 | 2.23 | 0.074 |
| Residual | 70 | 82.36 | 1.18 | ||
| Lack-of-fit | 30 | 49.9 | 1.66 | 2.05 | 0.017 |
| Replicates | 40 | 32.45 | 0.81 | ||
| Total | 79 | 474.08 | |||
| Variance Components Analysis | |||||
| Source of Variation | Measurement Characteristic | Variance Component | % of Total | Standard Deviation | |
| Lack-of-fit | Within-lab reproducibility | 0.41 | 34 | 0.64 | |
| Replicates | Repeatability | 0.81 | 66 | 0.90 | |
| Total | Method variation | 1.22 | 100 | 1.10 | |
The measurement system’s performance can be assessed using the process performance capability index (Ppk):
Ppk = A/B
where A = minimum (USL – Average, Average – LSL)
and B = 3 (standard deviation).
A generally accepted minimum value for Ppk is 1.33, which is consistent with 0.006% of the test results being outside of the specifications. This calculation assumes that the measurement process is stable and the measurement variation follows a normal distribution. Process performance capability indices are applicable to measurement processes because measurement is a process.
| Data Set | N | Average | Standard Deviation |
Ppk | Lower Ppk | Upper Ppk |
|---|---|---|---|---|---|---|
| All analysts | 96 | 99.4 | 0.69 | 1.18 | 1.00 | 1.36 |
| Analyst A | 46 | 99.5 | 0.85 | 0.98 | 0.75 | 1.20 |
| Analysts B, C, D, E, F | 50 | 99.4 | 0.51 | 1.57 | 1.25 | 1.90 |
Table 7 summarizes the Ppk index for the potency test method data (Figure 1, Tables 1 and 2). As expected, the Ppk value for analysts B, C, D, E, and F (Ppk = 1.57; 95% confidence limits 1.25–1.90) is higher than that for analyst A (Ppk = 0.98; 95% confidence limits 0.75–1.20). These results were confirmed when the test results were compared to specifications (target measurement uncertainty = 90–110) and the Ppk values and their 95% confidence limits were examined.
The capability analysis is useful because it compares the measurement variation to the specification limits (acceptance criteria) of the test method. The frequency of out-of-specification results is done as part of the analysis.
One of the outputs of the analytical target profile is a set of acceptance limits that are the same as specifications for the output of the measurement.4 As noted previously, the acceptance limits in this case were 90–110.
The sample size used to estimate the Ppk capability index is a critical consideration. Capability indices require larger sample sizes than might be expected. From a practical perspective, the sample should contain data that represent the total range of product values that the method is expected to measure. For example, if the total range of values for a particular measurement typically seen for a product is 90–110 and the data set contains values that range from 92 to 98, the sample is not representative of the total range of values.
From a statistical perspective, capability indices are highly variable when estimated from small samples. Studies have shown that, at a bare minimum, the sample size should be larger than 30–60, with the preferred sample size being greater than 60–90.14 Additional data on the uncertainty associated with the capability indices can be found in reference 14. That analysis shows that the length of the confidence intervals is wide, even for a sample size of 60.
Reporting the lower confidence limit for the performance capability index is a conservative strategy that takes sample size into account. For example, consider a sample of size 30, for which Ppk equals 1.30. This is close to the preferred minimum of 1.33, but the confidence limits are wide (1.02–1.76). By reporting ”performance capability index = 1.02 (lower 95% confidence limit),” we have reported a performance capability index that has taken the limited sample size into account. Of course, the lower confidence limit can be increased by increasing the sample size.
Risk of Lack of Management Attention
We often hear the comment that test methods receive insufficient attention from management. If management put test methods higher on their priority list, more resources would be made available to support measurement systems, which would in turn increase the chances that better measurement systems will emerge. One way to get management attention for test methods is to include method performance data as part of the management review of production data. Such an approach is shown in Figure 4.15 This strategy seems reasonable because the test methods are used to produce the production data.
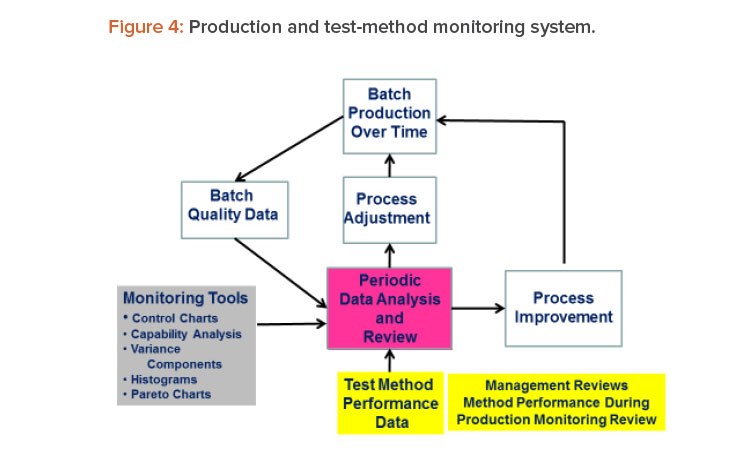
Figure 4 is a schematic of a system that links method performance data with the process, its data and analysis, management review, process adjustment, and process improvement. Process adjustments are changes made to bring the process back to target and/or within specifications. Process improvements are process changes made to correct problems in process performance. Process improvements typically result from team-led process improvement projects using an improvement framework such as define, measure, analyze, and improve and control (DMAIC).16
This results in a system for CMPV as well as continued process verification, as called for in the FDA guidance.2, 3 When we add test-method performance data to the system, we achieve CMPV as recommended in the USP guidance.4 Although this article focused on the monitoring of test-method measurements, out-of-specification, out-of-trend, and system-suitability-failure events can also be added to the metrics monitored.
I refer to management review as the “secret sauce.” Requiring periodic management review of measurement systems is a giant step forward toward the long-term sustainability of effective measurement systems. Management review is a “team sport” done by different management teams at different times. These teams include process operators (daily/hourly), area management (weekly), site management (monthly), and business management (quarterly). The management review plan should be devised to suit the needs of the business. Test-method performance would typically be assessed less frequently (e.g., monthly or quarterly) than process performance. The schedule selected will, of course, depend on the specific needs of the organization involved.
Trust but Verify
The admonishment to “trust but verify” applies to the monitoring of test methods. The tools described in this article provide an effective check on test-method stability and capability, and they reduce risk. The use of blind control samples is effective. The use of product stability data also works; this method is a broader and more robust verification check and reduces cost. Commercially available software can be used to carry out the calculations and analyses required for the proposed approaches. The proposed systems approach with integrated management review helps maintain the stability of test methods over time. This results in reduced risk of poor manufacturing process performance and defective pharmaceuticals reaching patients.
About the Author



